Why use Windows Containers?
When creating database applications we need consistency in all our environments to ensure quality releases. Traditionally developers might have their own instance of SQL Server on their workstation to develop against. Database projects would be created in SSDT and pushed to source control when ready for testing. If you’re not using SSDT for database development already, then you should seriously consider it to make your life easier and increase the quality of your releases. Ed Elliot explains why in this blog post.
A problem with CI for databases is that databases are a shared resource serving many users. An application can be atomic and tested independently very easily. On the build server when we build and deploy our database for testing, we need to ensure that we do not create problems by interfering with other builds. For example if you take a feature branch and push that to the build server, if someone else has done that on their feature branch there is potential for code to be deployed to the same CI database server and increase the rate of false build failures.
Here is how the development cycle might look in the common way:
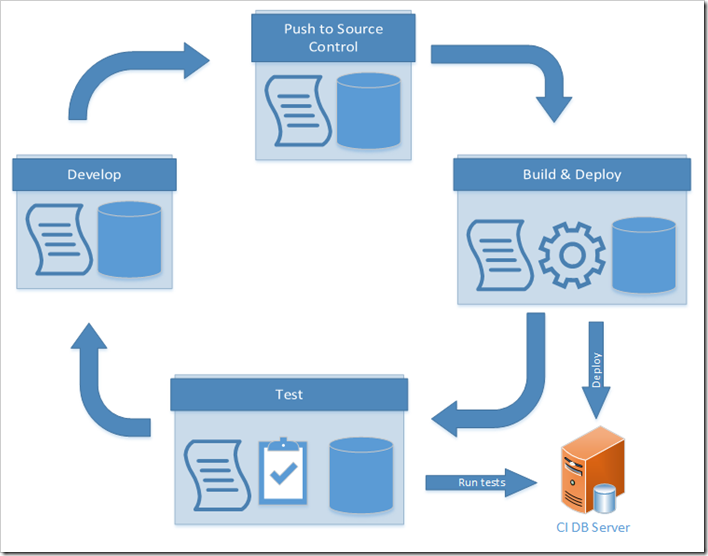
This is where containers can help.
Containers will give you a known, isolated environment for you to test your code in. You will not interfere with anyone else and the environment will be exactly the same every single time you deploy to it. There are some issues to overcome, but I’ll show you how to deal with those here. Every time you run a build and deploy, the process will create a container for you to deploy to that is isolated from all other builds.
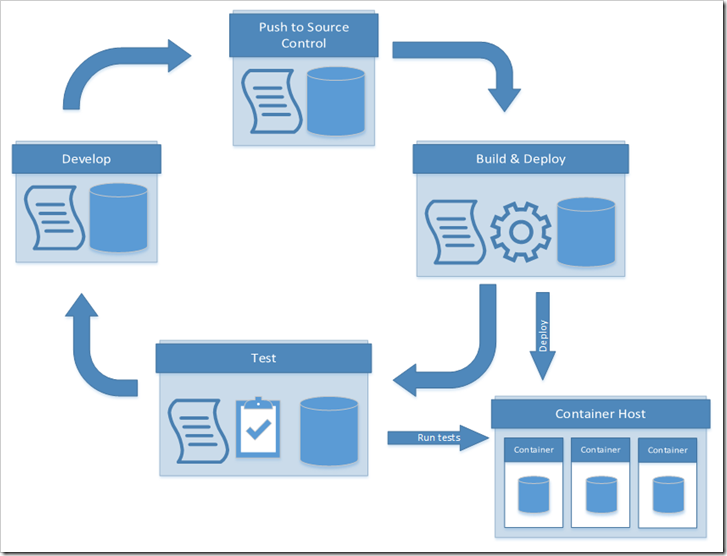
I have a test project on GitHub for you to play with here: https://github.com/markallisongit/mssql-docker-demo
Pre-Requisites
Before we get started, if you want to follow along, we have some pre-requisites to do. I won’t go into detail on how to perform each of these steps for brevity, but it’s not hard and there’s plenty of information online.
- Install Visual Studio and SSDT on your workstation. Clone the project onto your workstation.
- Build yourself a Windows Server Jenkins VM. Install Visual Studio with SSDT on this build server and make sure you can build and deploy database projects with it.
- Build yourself a Windows Server VM to host your SQL Server containers. For this you will need to install the Windows Containers feature. You could do this on the build server, but that has enough to do on its own and prefer to allocation SQL Server container resources in a separate VM (or physical host if you have a lot of database builds happening).
- Install the mssql-server-windows-developer docker image from docker hub on the Docker Host VM.
- Optionally create your own git server (I use GitLab CE for messing around with projects like this), but you can also use GitHub or VSTS.
We will use Jenkins as the build tool for this because it’s free and you can follow along. Create a multibranch pipeline project and link it to your source control. In Jenkins in Branch Sources, set it to: https://github.com/markallisongit/mssql-docker-demo.git. There is a config file in the project called config.json. Change the DockerHost to your own Windows Server 2016 box that has the containers feature running and push it back to your own source control repo.
Jenkinsfile
In Jenkins, the best way to control a build is to use pipelines configured using a groovy script in a file called the Jenkinsfile. The Jenkinsfile for this project is broken down into the following stages:

- Checkout: Get the source code from the git server.
- Build: Run MSBuild to build the database solution
- Create container: Create the MSSQL container on the Windows Container server.
- Deploy: Deploy the dacpac created in the Build step to the Windows Container we just created.
- Test: Run our Pester tests
- Cleanup: stop and remove the container we just created.
Let’s go through each of those steps in more detail by walking through the Jenkinsfile
Checkout
In Jenkins multibranch pipeline jobs, the build server will retrieve whatever branch has been changed on the git server. So if you’ve pushed a new feature branch for the project, you will see that Jenkins will create a new branch (if you have webhooks or polling enabled) and start a build. This step will checkout the branch concerned.
Build
bat "\"${tool 'MSBuild'}\" single-pipeline-demo.sln"
In Jenkins, if you install the MSBuild plugin you can configure different MSBuild versions. Go to Manage Jenkins –> Global Tool Configuration and set the path there.

This will run the tool MSBuild against our test project.
Create Container
Have a look at the CreateContainer.ps1 in a separate window and let’s break it down. All we’re doing is:
- Line 4. Read the
config.jsonconfig file. - Lines 6-15. Scanning the ports on the Windows Container server for a spare port starting from the port number in the config file (I’ve set it to 50000).
- Lines 17-22. We create a container on the remote Windows Container server over WinRM using the docker run command and set the name of it to mssql-{BRANCH_NAME}-{PORT-NUMBER}. We set the sa password of SQL Server to the one configured in the config file (this could be changed to be read from a secure location if you wanted). The port number that SQL Server listens on is set to the spare port number found in the previous step.
- Lines 24-42. We wait for the container creation and SQL Server service to start. We poll it every second and attempt a login to SQL Server using the sa account.
- Line 45. At this point the container is running and we can log in with sa. We then write our configuration out to a file on the build server for other steps to use later on. This is a json file called ContainerInfo.json and has the port number and the container name stored in it.
Note
Deploy
Now that we have our container created, let’s deploy our dacpac with a PowerShell script called Deploy.ps1. Breaking this down we are simply doing:
- Lines 3,4. Reading the config.json and the containerinfo.json files.
- Lines 5-10. Initializing our variables from the configuration.
- Line 16. Create a new WinRM session to the Windows Container host.
- Line 17. Create a directory on the docker host called C:\Temp so we can demo copying files to the container from the build server.
- Line 18. Copy our test file (in this case I’m just using the ContainerInfo.json file to the directory created in step 4. This could be a CLR or xp, or whatever file(s) you need to be in the container.
- Lines 20-26. In the WinRM session, we run docker exec to execute a batch command in the container. This creates a new directory in the container. Next we have to wait 5 seconds (don’t know why) and copy the files we want from the Container Host into the container with the docker cp command.
- Line 30. Destroy the WinRM session.
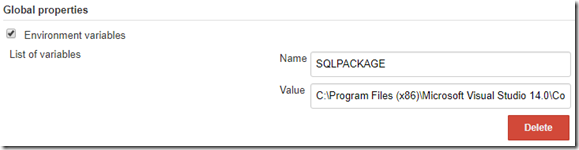
- Line 32. Run sqlpackage.exe on the build server to deploy to dacpac the container. Notice that I am using an environment variable for SQLPACKAGE so that if the path changes it can easily be done.
For step 8, go to Manage Jenkins and input your SQLPACKAGE location in Global Properties –> Environment variables like so:
Test
Now that we have our code built and deployed to a container we can run tests on it to make sure the code is doing what it should, and then pass or fail this build. I have written a very basic pester test in file Deploy.Tests.ps1 that queries the SQL Server and makes sure that the table in the project exists.
The test does the following:
- Reads the configuration files created earlier in the build.
- Imports the SqlServer module so we can use Invoke-SqlCmd.
- Runs a query using Invoke-SqlCmd to check the existence of the table.
Make the tests as comprehensive as you like, I just want to demo something simple so only have the one here.
Cleanup
In a finally clause in our Jenkinsfile we have stage Cleanup to destroy the container we created so we free up server resources for other builds. Looking in the PowerShell script Cleanup.ps1:
- Lines 5-6. Read config
- Lines 8-10. Stop the container.
- Lines 12-14. Destroy the container.
- Steps 2 and 3 can be combined into one command if you prefer– see the docker documentation for details.
Notify in the Catch clause
In the Jenkinsfile notice that I have a catch block which will notify me if the build fails by email and slack. I have configured Jenkins to post build failures to a slack channel so will be notified on my phone if the build fails in the slack app.
Archive build artifacts
I have not included archiving of artifacts in this demo for brevity. Usually I will test the BRANCH_NAME variable in the Jenkinsfile and archive build artifacts for main branches of code e.g. master, develop, release, hotfix and not bother with archiving feature branches. Feature branches are usually named the same as the JIRA ticket and then merged into develop branch once tests pass on the build server and after peer review.
Conclusion
Feel free to build on and share improvements to the above process in the comments below, hope this has been helpful and interesting to you as we enter the new world of containers (at least in the Windows world).