On a client site recently a question was asked about the file share witness in a SQL Server failover cluster on-premises, and where to put it if you only have two sites. As always, it depends! Let’s look at some scenarios. Bear in mind that use of the Azure Cloud Witness requires Windows Server 2016 or later.
Topology 1
Three node cluster with 2 nodes at primary and 1 at disaster recovery (DR)
Most people want high availability at their “primary site” and are happy to have standalone capability at the business continuity (DR) site. To save storage costs, I would recommend a SQL Server failover clustered instance so you only have one set of storage at the primary site. On top of that you can place an availability group in asynchronous mode to a standalone server at your DR site. In this configuration there are several scenarios to consider, and they can all be served with a file share witness at the primary site, or use a cloud witness in azure.
Scenario 1: Loss of one node at the primary site
This will be a seamless, automatic failover to the passive node at the primary site using either the File Share Witness (FSW) or optionally the Azure Cloud Witness (ACW). The SQL Server instance should be back online within a minute or so depending on how long recovery takes and how many and how large in-flight transactions were at the time of the failure.
Scenario 2: Loss of the primary site
In a disaster situation due to flooding, fire, etc, a manual failover to DR site must be done. In this situation the ACW is not required. We failover to the DR site and force quorum.
On the DR node in PowerShell:
stop-service clussvc
start-clusternode myDRNode -FixQuorum
(get-clusternode -name "myDRNode").Nodeweight = 1
Switch-SqlAvailabilityGroup -Path SQLSERVER:\Sql\myDRNode\Instance\AvailabilityGroups\MyAg -AllowDataLoss
Then set the nodeweights to 0 for your primary nodes as you don’t want them having votes when you are at the DR site with forced quorum. At this point you will be up and running again at the DR site but in an exposed state until you fix your primary data centre.
Scenario 3: Loss of the DR site
In this situation nothing happens because the DR site does not have a vote. The failover clustered instance keeps running and all seems well. Or is it?Winking smileSQL Server will now be unable to truncate the log after a log backup because the log records are required to be sent to the secondary replica at DR. This has now disappeared so what do we do? The send queue will grow as changes are made to the primary replica. If the DR site is expected to come back online within a few hours, then the only action that is required is to monitor the send queue on the primary and disk space where the transaction log files are. Once the DR site comes back online, the send queue should drain records to the secondary replica automatically and the next log backup will free up space within the transaction log files. Note, the files themselves will not shrink, so if you are really tight on space you may want to schedule a shrink operation on your transaction log files.
If the DR site is expected to be down for a while, then remove the replica from the availability group so that the send queue does not fill up the disk on the primary. When the DR site comes back you will need to join it back in the same way as when you set it up with a restore of the database and logs.
Topology 2
A single node at the primary site with a synchronous replica at the DR site.
Typically the primary and DR sites are not marked as such, they are just sites. So if one of the sites is lost temporarily, the other site will take over. This situation lends itself really well to the Cloud Witness because you can combine HA and DR together without needing a third site for the File Share Witness or a Shared Disk. These sites need to be physically close usually within 20 miles or so with good connectivity.
Scenario 1: Temporary loss of a site
If a site is lost temporarily, then the cloud witness will act as a vote to failover automatically to the other site and the business can keep running. As long as the site comes back online within a short period of time, the send queue should not grow too large.
Scenario 2: Extended loss of a site
This is more problematic, however the business will still keep running thanks to the Cloud Witness. It doesn’t matter which site was primary and which one was lost, because the cloud witness is off-site. If a FSW had been used then the cluster would stop and there would be extended down time whilst engineers/DBAs forced quorum manually. After automatic failover, a DBA should remove the other replica from the availability groups in order to keep the send queue to a manageable size.
Set up a Cloud Witness
There are many other topologies out there that we’ve encountered, but for the sake of brevity let’s get into how to implement the Cloud Witness.
Requirements
- An azure account
- Windows Server 2016 on your cluster nodes.
At Sabin.IO we use PowerShell quite often for automation, so rather than show you the GUI, here’s how to do it in PowerShell. I have set up a Cloud Witness in a lab setting with the same configuration as Topology 1.
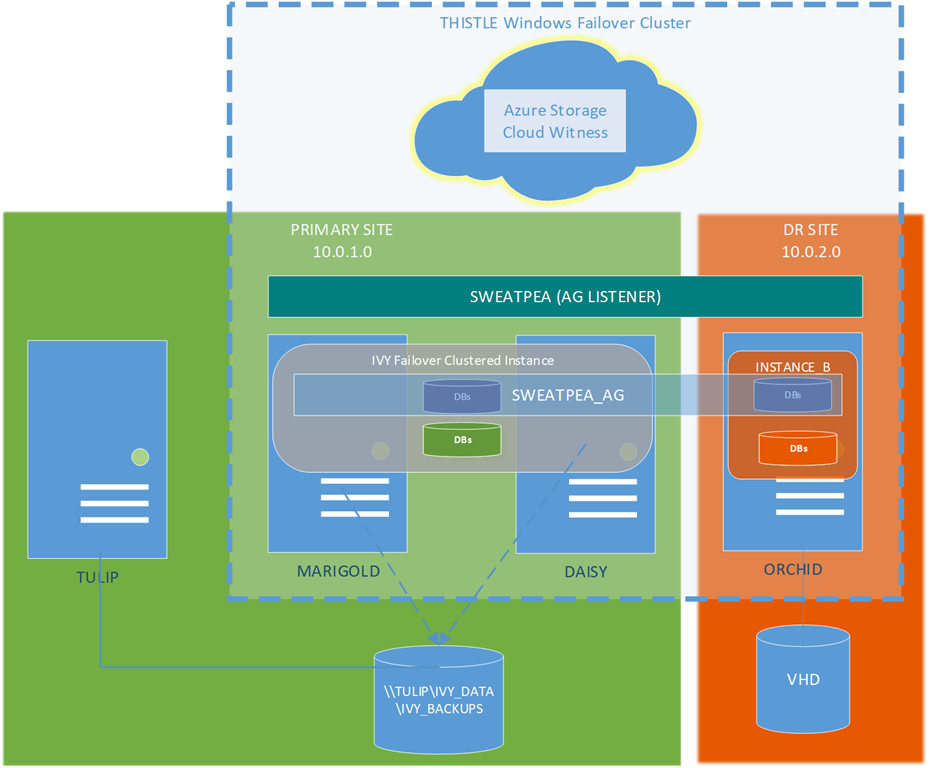
To set up the Cluster you just need to do this in PowerShell. I’ve commented it heavily so you know what’s going on:
# runs on windows 10
$nodes = ( "marigold", "daisy", "orchid")
$FCInodes = ("marigold","daisy")
$clusterName = "thistle"
$clusterStaticIPs = ('10.0.1.9','10.0.2.9')
$cloudWitnessLocation = 'North Europe'
$resourceGroup = "$clustername-rg"
$storageAccountName = "$($clustername)sa"
$FCIServiceAccount = 'duck\sv_sql_ivy'
# add the service account to the local admins group on the FCI Nodes
$FCInodes | % {
Invoke-Command -ComputerName $_ -scriptblock {
Add-LocalGroupMember -Group "Administrators" -Member $using:FCIServiceAccount
}
}
# install the windows clustering feature on all nodes
$result = $nodes | % {Install-WindowsFeature -ComputerName $_ -Name Failover-Clustering -IncludeManagementTools }
if (($result | ? {$_.Success -ne $true}).Count -gt 0) {
throw "Failed to install failover clustering"
}
# need RSAT installed first on your local workstation. If you don't want that, just run it on the server. This CANNOT be run over WINRM, sorry!
$result = Test-Cluster -Node $nodes
# Create the cluster
$result = New-Cluster -Name $clusterName -Node $nodes -StaticAddress $clusterStaticIPs
if ($result.Name -ne $clusterName) {
throw "Cluster creation failed"
}
# this must be run before installing SQL Server
$result = Test-Cluster -Node $nodes
# login to Azure
Login-AzureRmAccount -Subscription 'Sabin.IO - dev+test+demo'
Select-AzurermSubscription -Subscription 'Sabin.IO - dev+test+demo'
# Create a Resource Group for the Cloud Witness
New-AzureRmResourceGroup -Name $resourceGroup -Location $cloudWitnessLocation -Force
# Create a storage account for the Cloud Witness (must be unique within Azure)
New-AzureRmStorageAccount -ResourceGroupName $resourceGroup `
-Name $storageAccountName `
-Location $cloudWitnessLocation `
-SkuName Standard_LRS `
-Kind StorageV2
# Get the access key for the storage account
$accesskey = (Get-AzureRmStorageAccountKey -StorageAccountName $storageAccountName -ResourceGroupName $resourceGroup | ? {$_.KeyName -eq 'key1'}).Value
# Configure the cluster to use the azure storage account as the Cloud Witness
$result = Invoke-Command -ComputerName $clusterName -scriptblock { Set-ClusterQuorum -CloudWitness -AccountName $using:storageAccountName -AccessKey $using:accesskey }
# let's have a look
Get-Cluster -Name thistle | Get-ClusterResource
The last command returns this:
Name State OwnerGroup ResourceType
---- ----- ---------- ------------
Cloud Witness Online Cluster Group Cloud Witness
Cluster IP Address Online Cluster Group IP Address
Cluster IP Address 10.0.2.9 Offline Cluster Group IP Address
Cluster Name Online Cluster Group Network Name
SQL IP Address 1 (IVY) Online SQL Server (IVY) IP Address
SQL Network Name (IVY) Online SQL Server (IVY) Network Name
SQL Server Online SQL Server (IVY) SQL Server
SQL Server Agent Online SQL Server (IVY) SQL Server Agent
SQL Server CEIP (MSSQLSERVER) Online SQL Server (IVY) Generic Service
SweetPea-AG Online SweetPea-AG SQL Server Availability Group
SweetPea-AG_10.0.1.28 Online SweetPea-AG IP Address
SweetPea-AG_10.0.2.28 Offline SweetPea-AG IP Address
SweetPea-AG_SWEETPEA Online SweetPea-AG Network Name
The cluster is now set up over two physical sites and with a witness for the cluster in the Cloud.
Nice.